Tokenization - 1: Why the First Step Shapes Everything
I want to do a simple experiment and look into how language models approach different languages. So let me show you something before we get into anything technical.
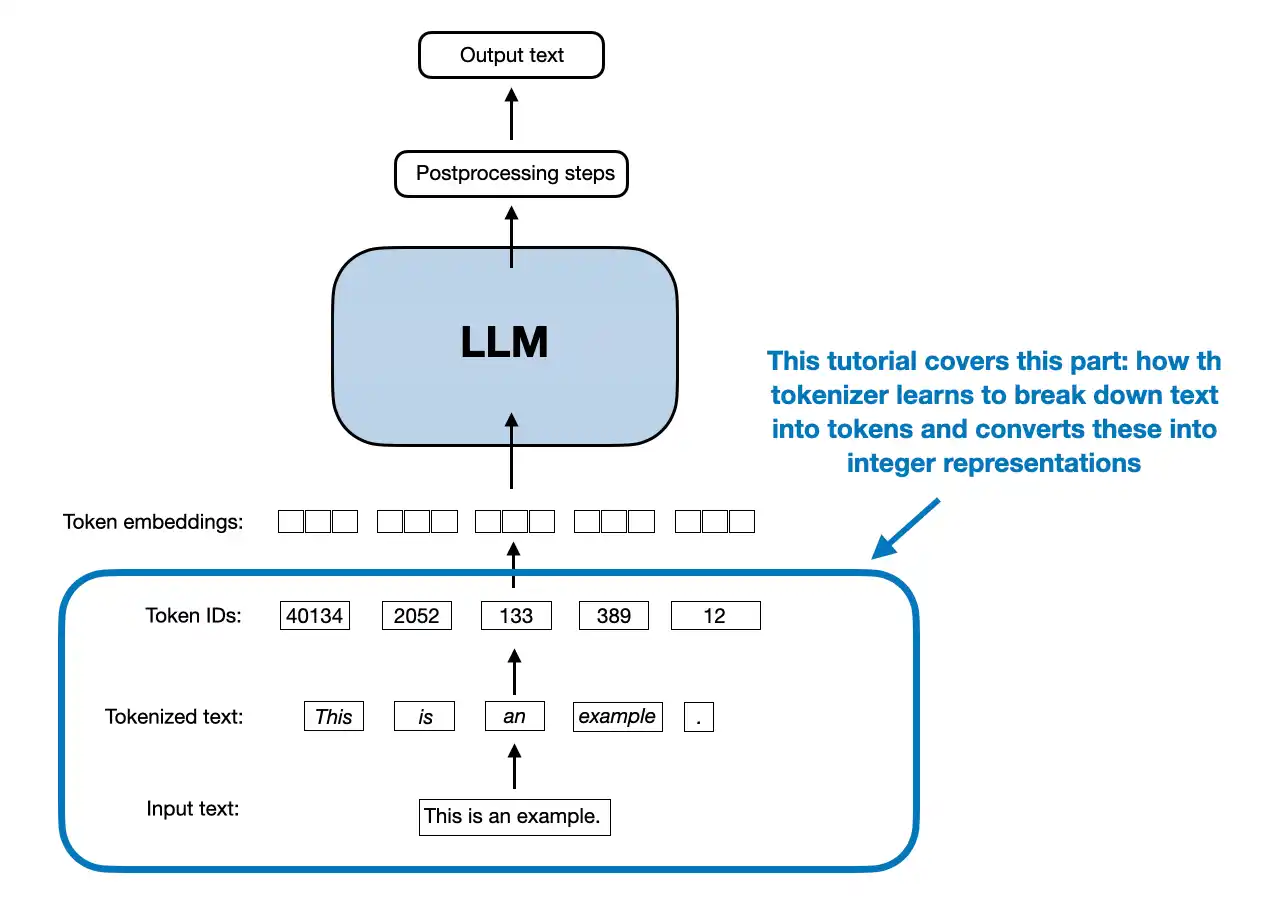 The diagram illustrates the tokenization process used in LLMs. Raw text is first split into smaller units called tokens, which are then mapped to unique token IDs that the model can process numerically. This conversion enables the model to understand and generate text based on sequences of tokens. Source: Sebastian Raschka
The diagram illustrates the tokenization process used in LLMs. Raw text is first split into smaller units called tokens, which are then mapped to unique token IDs that the model can process numerically. This conversion enables the model to understand and generate text based on sequences of tokens. Source: Sebastian Raschka
I am asking the same question in three languages with the gpt-4 / gpt-3.5-turbo / text-embedding-ada-002 tokenizer.
English
"Hey man, how's it going?"
Token splits: ["Hey"] ["man,"] ["how's"] ["it"] ["going"] ["?"]
Token IDs: [19182, 11, 1268, 596, 433, 2133, 30]
Token count: 8 tokens
Each word gets its own token, clean, efficient, one token roughly per word.
Hindi
"हे, सब कैसा चल रहा है?"
Token splits: ["हे"] ["◈"] [","] [" सब"] [" क"] ["◈"] ["◈"] ["स"] ["◈"] [" च"] ["ल"] [" र"] ["ह"] ["◈"] [" ह"] ["◈"] ["◈"] ["?"]
Token IDs: [95048, 35470, 11, 69258, 5619, 105, 48909, 12906, 230, 79468, 24810, 15272, 248, 92911, 15272, 108, 95048, 24810, 85410, 12906, 230, 30]
Token count: 22 tokens
Contexually its the same sentence. Now every character is fragmented into multiple byte-level pieces. The tokenizer never learned to merge Hindi byte sequences efficiently.
Telugu
"హే, ఎలా సాగుతోంది?"
Token splits: ["హే"] ["◈"] ["◈"] [","] [" ఎ"] ["◈"] ["లా"] [" స"] ["◈"] ["గు"] ["తో"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["◈"] ["?"]
Token IDs: [32405, 117, 53898, 229, 11, 94355, 236, 32405, 110, 32405, 122, 94355, 116, 32405, 122, 32405, 245, 53898, 223, 32405, 97, 53898, 233, 32405, 224, 32405, 99, 32405, 123, 30]
Token count: 30 tokens
18 characters. 30 tokens. Each Telugu character breaks into 2 to 3 raw bytes that the tokenizer treats as separate units.
Same meaning, same model, but Telugu costs 4x more tokens than English. Imagine building a product where non-English speakers pay 4x more, get 4x less context, and the model performs worse on their language, all because of a design choice made before training even started. That choice is the tokenizer.
Language models do not read text. They read integers. Every input, text, emoji, and number gets converted into a sequence of integers before the model sees anything. We call those integers tokens. How that conversion happens shapes everything, cost, speed, context length, and how well the model handles your language.
Every token matters at scale.
Basics
Before any forward pass in LLM, input text gets converted into a sequence of integer IDs. Each ID maps to a token, which has a learned embedding that the model uses for all downstream computation.
"Hey Siri, set an alarm for 6 am" → [19182, 76074, 11, 743, 459, 17035, 369, 220, 21, 1097]
Those integers are just indices into an embedding table. The tokenizer decides what the atomic units are, and the model learns a vector representation for each one.
There are three main ways to define those units. All three have been tried. In practice, subword tokenization became the standard tradeoff.
Three approaches
1. Word level
Split on spaces. Each word is a token.
text = "account flagged for SIM swap activity"
tokens = text.split()
# ['account', 'flagged', 'for', 'SIM', 'swap', 'activity']Simple. Works for a few thousand common English words.
Breaks on everything else. English has 170,000 words in active use. Add variants like run, runs, running, ran, runner and you need millions of entries. Anything out of the vocabulary becomes [UNK]. The model sees nothing.
There is also no sharing between organize, organization, organizations, and organizational, even though they carry related meaning. The model has to learn each one from scratch.
2. Character level
Each character is a token. Tiny vocabulary, maybe 256 entries for ASCII.
text = "chargeback"
tokens = list(text)
# ['c', 'h', 'a', 'r', 'g', 'e', 'b', 'a', 'c', 'k']No unknown tokens ever. Any input is always representable.
But a 500-word paragraph becomes 2500 character tokens. Attention scales quadratically with sequence length, so this is a direct hit to compute cost and effective context. The model also wastes capacity learning that c-a-t and c-a-t-s differ by one character, which should be irrelevant to meaning.
3. Subword
The practical middle ground. Split at a learned boundary between characters and words.
Common words stay whole. Rare words decompose into reusable pieces.
"tokenization" -> ["token", "ization"]
"chargebacks" -> ["chargeback", "s"]
"undetected" -> ["un", "detected"]
Vocabulary stays manageable, typically 32K to 256K entries. No [UNK] tokens because any word can decompose all the way to characters if needed. Morphological relationships emerge naturally, organize, organization, and organizational all share the organiz subword, so the model does not learn them from scratch.
This is what every major LLM uses today. The only remaining question is which subword algorithm.
What tokenization actually controls
Most people treat tokenization as preprocessing. It is not. It is a structural decision that shapes every downstream property of the model.
1. Vocabulary size and memory
A 32K vocabulary at 4096 dimensions in float16 is 256MB just for embeddings. GPT-4 uses a 100K vocabulary, roughly 800MB at similar dimensions. Larger vocabularies compress text into fewer tokens but cost more memory, so there is a real tradeoff between sequence length and embedding table size.
2. Context capacity
Your 128K context window holds 128K tokens, not words, not characters. If your tokenizer produces 3x as many tokens for Hindi text as for English, Hindi speakers effectively have a 43K context window on the same model. The window does not grow to compensate.
3. Multilingual fairness
English in UTF-8 is usually one byte per character. Hindi Devanagari is usually three. Byte-level tokenizers start from those raw bytes, but the bigger factor is training data distribution. If the tokenizer is trained mostly on English text, English byte patterns appear more often and receive more merge operations. Hindi appears less often, so it stays fragmented into more tokens.
4. API cost
Most LLM APIs price by token. If you send a document that is 10,000 words in English and 10,000 words in Japanese, the Japanese document can cost 3 to 4x more tokens. Same semantic content. Different price.
5. Arithmetic and character reasoning
If "12345" tokenizes as ["123", "45"], the model never has access to the individual digits in a clean way. It has to reconstruct place-value arithmetic from arbitrary token boundaries. This contributes to why LLMs struggle with digit counting, syllable counting, and multi-digit math. The model has to recover structure that humans see immediately.
Byte-level insight
Modern tokenizers, GPT-4, Llama 3, Gemma, use byte-level BPE. Instead of starting with characters, they start with bytes.
UTF-8 encodes any text in the world as a sequence of bytes in the range 0 to 255. The initial vocabulary is always exactly 256 tokens, one per byte value. The merge rules are learned from training data, so which byte sequences become common tokens depends entirely on the corpus.
The BPE merge process runs from there, which means no [UNK] tokens ever. Emoji, code, URLs, and Chinese characters are all representable without special handling.
The cost is that non-Latin scripts require more bytes per character in UTF-8. Chinese and Devanagari are 3 bytes each, Arabic is 2 bytes, so they start with more initial tokens before merges happen. Larger vocabularies and more balanced training data reduce this gap, but do not eliminate it.
How vocabulary size evolved
| Model | Tokenizer | Vocabulary |
|---|---|---|
| BERT 2018 | WordPiece | 30K |
| GPT-2 2019 | Byte Level BPE | 50K |
| T5 2019 | SentencePiece Unigram | 32K |
| GPT-4 2023 | Byte Level BPE tiktoken | 100K |
| Llama 3 2024 | Tiktoken BPE | 128K |
| Gemma 2024 | SentencePiece BPE | 256K |
30K to 256K in six years. The algorithm debate is largely settled: byte-level BPE with optional SentencePiece wrapping. The active variable now is vocabulary size. Larger vocabularies compress text more aggressively, which means shorter sequences, faster inference, and better multilingual coverage. But there is a limit — if the vocabulary gets too large, many tokens become rare enough that their embeddings are poorly learned, and the softmax layer gets more expensive.
What comes next
This article covers the why. The next ones go into the how.
BPE from scratch: full Python implementation, byte level extension, the multilingual tradeoff with real token counts.
WordPiece and Unigram: how BERT's algorithm differs from GPT's, and why Unigram's probabilistic approach is underrated.
SentencePiece and production: why the pre-tokenization problem matters, which models use which tokenizer, and the unsolved problems that still cause LLM failures today.
Tokenization is the first compression layer of a language model. Before the transformer learns grammar, reasoning, or facts, the tokenizer decides what patterns the model can even see. Every capability after that is shaped by that first split.
Resources
- Neural Machine Translation of Rare Words with Subword Units - Sennrich et al. 2016, the paper that brought BPE to NLP
- tiktoken - OpenAI's production BPE tokenizer, Rust based and fast
- HuggingFace Tokenizers - supports BPE, WordPiece, and Unigram with a unified API